学习三大要素 what、why、how,每天给自己强调一遍
1:什么是IO
程序是由数据+指令构成的,运行程序的过程可以分成下面这几步:
将代码加载到内存中,逐条运行内存中的代码
在运行代码的过程中,可能需要对文件的读写,即将文件输入(Input)到内存和将代码执行结果产生的文件输出(Output)到外设(网络、磁盘)的过程。那么这个数据交换的过程就是I/O
1、将代码加载到内存中,逐条运行内存中的代码
2、在运行代码的过程中,可能需要对文件的读写,即将文件输入(Input)到内存和将代码执行结果产生的文件输出(Output)到外设(网络、磁盘)的过程。那么这个数据交换的过程就是I/O
2:演进方式
同步(如果由程序自己主动去读取IO,不管是什么IO模型都归属于同步IO,select,poll,epoll都是同步的):
阻塞IO模型
非阻塞IO模型
信号驱动IO模型
IO复用模型
异步IO模型
3:BIO(blocking io)
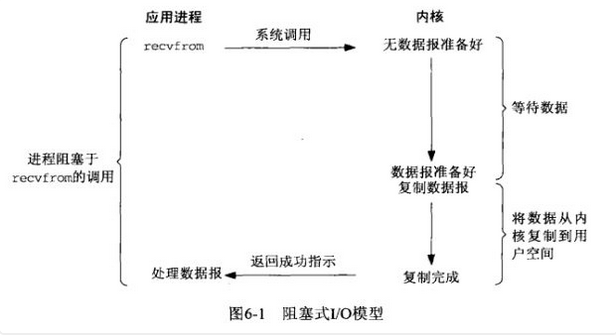
2个阻塞的方法: accept、recv
4:NIO(non block io)
linux 内核从2.6版本提供非阻塞api,使用用方式和BIO一样,但是要在阻塞前设置参数为非阻塞IO。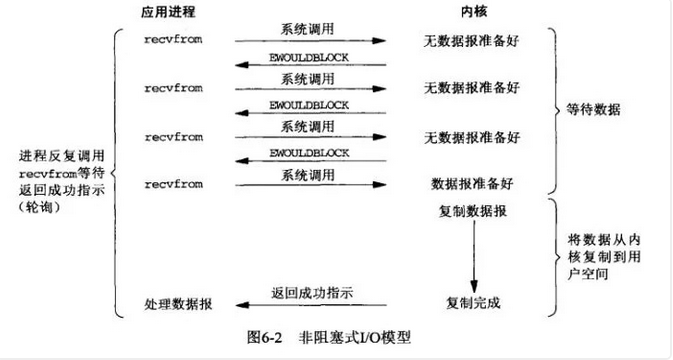
优缺点:
NIO大量的减少了需要的线程数,在BIO阻塞的时候,可以进行大量其他计算。
大量遍历连接调用recv,造成大量系统软中断(其中大量是无用的 O(n))。
5:IO复用模型 O(1)
由于NIO的瓶颈产生于大量的系统调用,假如解决这个问题是否就可以解决,于是多路复用io出现。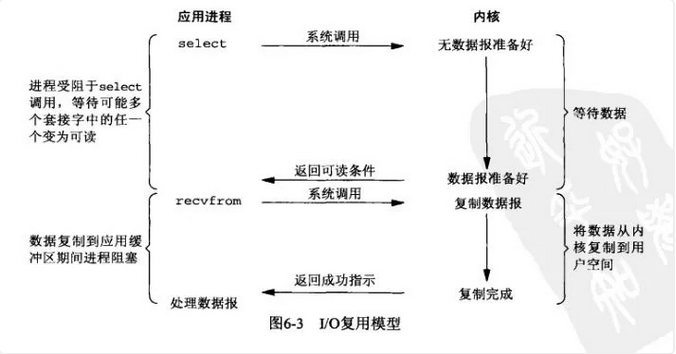
关键字 selelct poll
IO多路转接是多了一个select函数,多个进程的IO可以注册到同一个select上,当用户进程调用该select,select会监听所有注册好的IO,如果所有被监听的IO需要的数据都没有准备好时,select调用进程会阻塞。当任意一个IO所需的数据准备好之后,select调用就会返回,然后进程在通过recvfrom来进行数据拷贝。
优缺点:
通过一次调用,由内核进行遍历(内核速度更快,且不会新增软中断)
大量反复传递fds(文件句柄集合,解决方案,内核开辟空间保留fds)
每次select或者poll都要重新遍历内核空间中的fds,遍历问题并没有解决。
6:epoll
epoll是Linux内核为处理大批量文件描述符而作了改进的poll,是Linux下多路复用IO接口select/poll的增强版本,它能显著提高程序在大量并发连接中只有少量活跃的情况下的系统CPU利用率。另一点原因就是获取事件的时候,它无须遍历整个被侦听的描述符集,只要遍历那些被内核IO事件异步唤醒而加入Ready队列的描述符集合就行了。epoll除了提供select/poll那种IO事件的水平触发(Level Triggered)外,还提供了边缘触发(Edge Triggered),这就使得用户空间程序有可能缓存IO状态,减少epoll_wait/epoll_pwait的调用,提高应用程序效率。
重点:不需要遍历!
怎么实现的呢?
1、select低效的原因之一是将“维护等待队列”和“阻塞进程”两个步骤合二为一。每次调用select都需要这两步操作,然而大多数应用场景中,需要监视的socket相对固定,并不需要每次都修改。epoll将这两个操作分开,先用epoll_ctl维护等待队列,再调用epoll_wait阻塞进程(解耦)。显而易见的,效率就能得到提升。
2、select低效的另一个原因在于程序不知道哪些socket收到数据,只能一个个遍历。而epoll新增了一个就绪列表,收到数据的socket由内核加入到就绪列表(一个引用列表),就能避免遍历。
epoll_wait阻塞进程
当socket接收到数据,中断程序一方面修改rdlist,另一方面唤醒eventpoll等待队列中的进程,进程A再次进入运行状态(如下图)。也因为rdlist(就绪列表)的存在,进程A可以知道哪些socket发生了变化。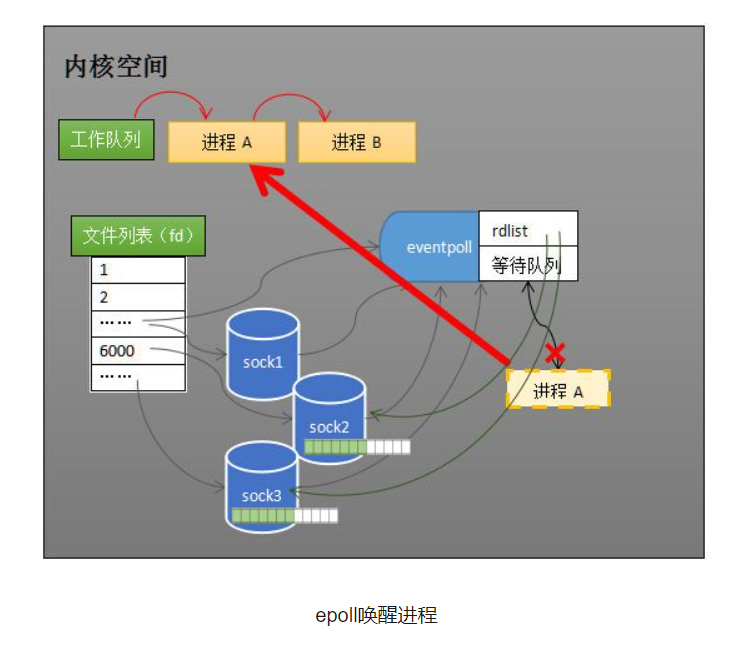
7:信号驱动IO模型
复用IO模型解决了一个线程可以监控多个fd的问题,但是select是采用轮询的方式来监控多个fd的,通过不断的轮询fd的可读状态来知道是否就可读的数据,而无脑的轮询就显得有点暴力,因为大部分情况下的轮询都是无效的,所以有人就想,能不能不要我总是去问你是否数据准备就绪,能不能我发出请求后等你数据准备好了就通知我,所以就衍生了信号驱动IO模型。
于是信号驱动IO不是用循环请求询问的方式去监控数据就绪状态,而是在调用sigaction时候建立一个SIGIO的信号联系,当内核数据准备好之后再通过SIGIO信号通知线程数据准备好后的可读状态,当线程收到可读状态的信号后,此时再向内核发起recvfrom读取数据的请求,因为信号驱动IO的模型下应用线程在发出信号监控后即可返回,不会阻塞,所以这样的方式下,一个应用线程也可以同时监控多个fd。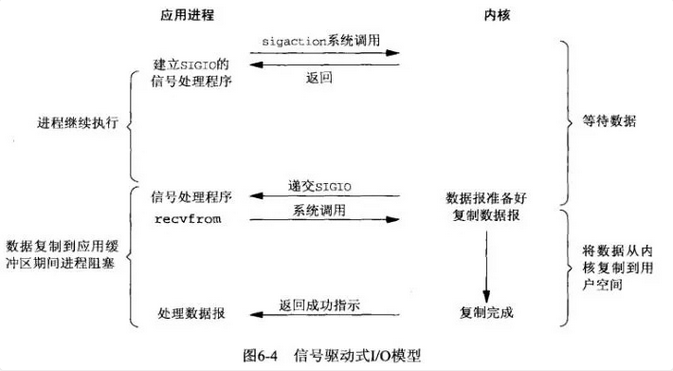
8:异步IO模型
也许你一开始就有一个疑问,为什么我们明明是想读取数据,什么非得要先发起一个select询问数据状态的请求,然后再发起真正的读取数据请求,能不能有一种一劳永逸的方式,我只要发送一个请求我告诉内核我要读取数据,然后我就什么都不管了,然后内核去帮我去完成剩下的所有事情?
当然既然你想得出来,那么就会有人做得到,有人设计了一种方案,应用只需要向内核发送一个read 请求,告诉内核它要读取数据后即刻返回;内核收到请求后会建立一个信号联系,当数据准备就绪,内核会主动把数据从内核复制到用户空间,等所有操作都完成之后,内核会发起一个通知告诉应用,我们称这种一劳永逸的模式为异步IO模型。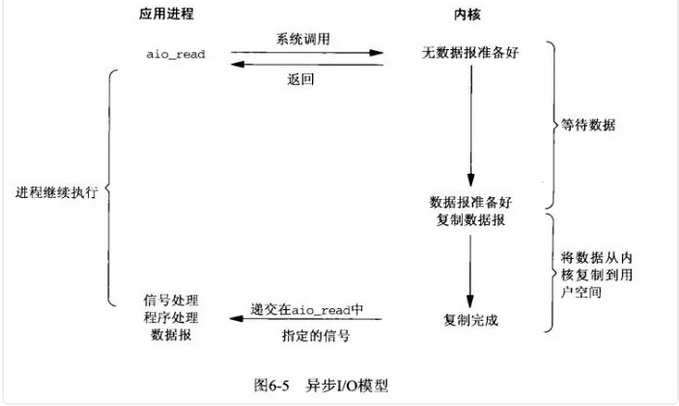
异步IO的优化思路是解决了应用程序需要先后发送询问请求、发送接收数据请求两个阶段的模式,在异步IO的模式下,只需要向内核发送一次请求就可以完成状态询问和数拷贝的所有操作。
9:总结
什么时候select优于epoll?
一般认为如果在并发量低,socket都比较活跃的情况下,select效率更高,也就是说活跃socket数目与监控的总的socket数目之比越大,select效率越高,因为select反正都会遍历所有的socket,如果比例大,就没有白白遍历。加之于select本身实现比较简单,导致总体现象比epoll好)
而网络IO大多数使用select/epoll,当然也可以自己把它们封装的使用起来就像异步IO。
异步和同步的唯一区别就是使用的方式不一样,一个要堵塞线程,一个不堵塞线程。
并不是说异步IO性能一定比同步IO优秀。磁盘性能就那样,用同步IO也可以把它压榨完。为什么非得用异步IO呢?如果你不想线程堵塞,那可以换成异步IO,3种方案随便选。如果你觉得同步IO性能差,那换成异步IO就一定会变好吗?如果非要说性能差,那并不是把同步换成异步就能搞定的,而是需要去看每种IO方式的IO链路,和对数据的拷贝次数,并结合自己的IO场景和需求去分析。



