一、ribbon入门
1、ribbon在微服务中是什么?起到了什么作用?
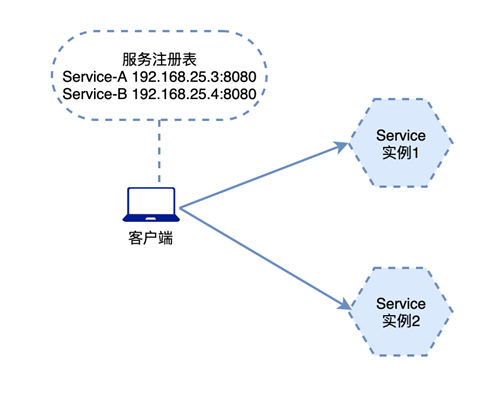
ribbon是一个客户端负载均衡,原来我们的http请求是 http://ip:port/**** 使用ribbon: productName那么也就是根据项目名,寻找一台服务, 然后将项目名定位到一台服务的过程.
2、重新定义ribbon负载均衡策略
public class TheSameClusterPriorityRule extends AbstractLoadBalancerRule {
@Override
public void initWithNiwsConfig(IClientConfig iClientConfig) {
}
/**
* 主要实现choose方法
*
*/
@Override
public Server choose(Object o) {
}3、feign也是客户端负载均衡与ribbon的区别(Ribbon VS Feign)
feign和ribbon是Spring Cloud的Netflix中提供的两个实现软负载均衡的组件,Ribbon和Feign都是用于
调用其他服务的,方式不同。Feign则是在Ribbon的基础上进行了一次改进,采用接口的方式。
将需要调用的其他服务的方法定义成抽象方法即可,不需要自己构建 http 请求.
4、如何自定义feign拦截器

二、ribbon按照权重实现负载均衡
ribbon本身是没有权重的概念的, 那么如何才能实现代用权重的负载均衡呢?
我们在nacos中,服务集群有一个权重的概念,当给服务器设置了权重,那么流量就可以根据权重比例分配到服务器上.
1、先来看看如何自定义一个负载均衡策略.
首先是继承自AbstractLoadBalancerRule. 从下面这张图可以看出,ribbon自定义的策略,最终都继承自这个类,这个类封装了负载均衡策略的公共方法.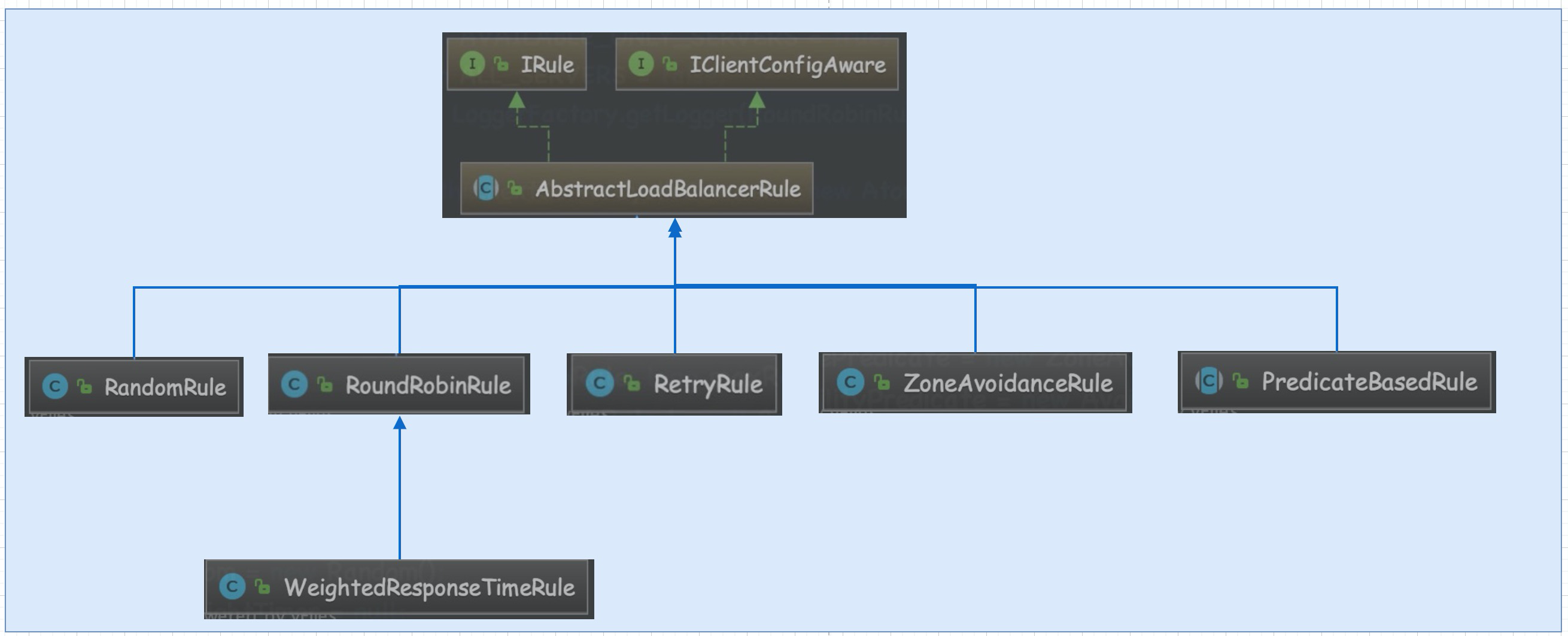
在nacos中可以配置服务器的权重
在nacos中,有两个重要的类,一个是NameService,一个是ConfigService
- NameService: 注册中心
- ConfigService: 配置中心
三、实现带有权重的负载均衡器
第一步:自定义一个带有权重的负载均衡器MyWeightRule
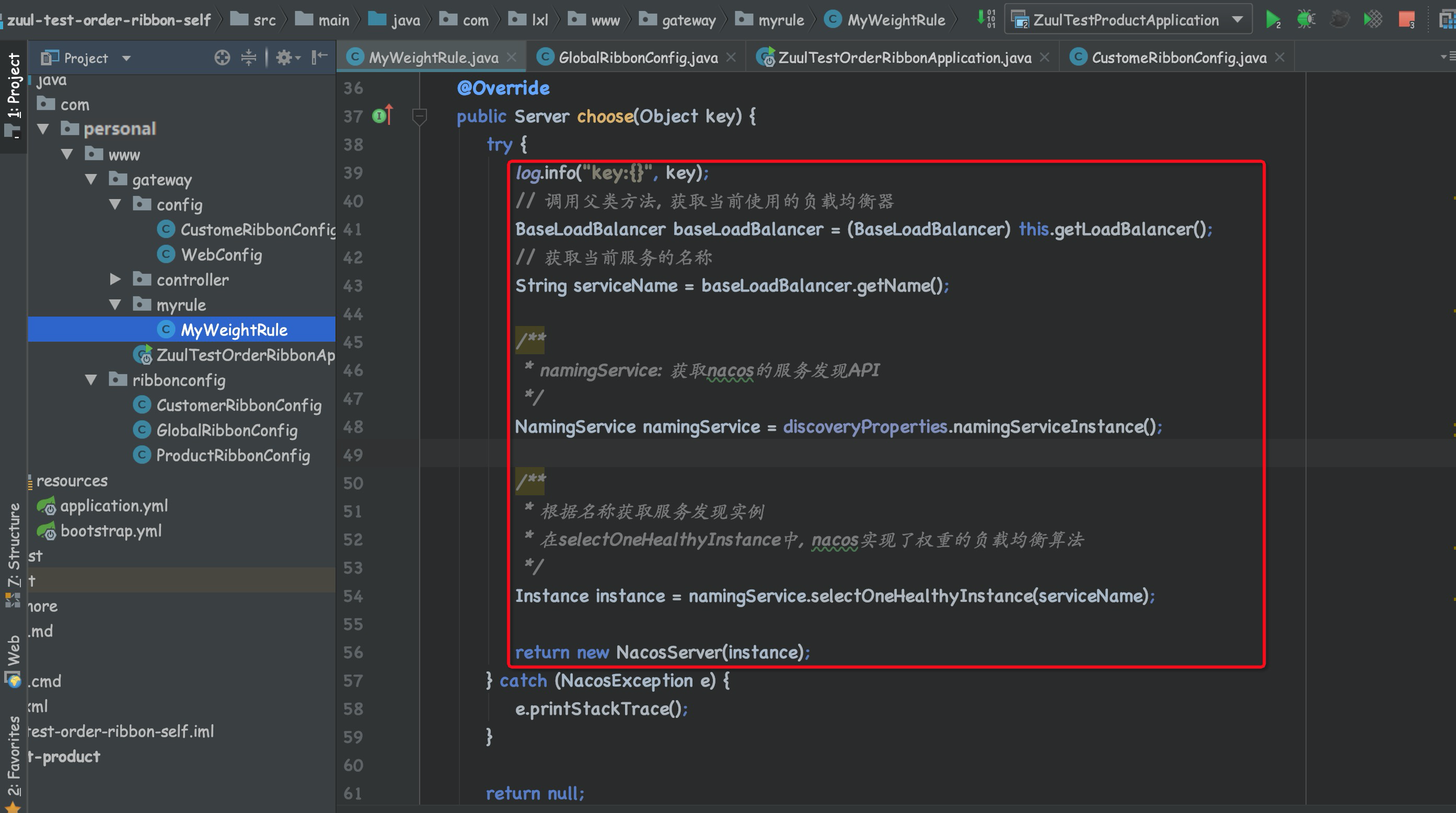
package com.personal.www.gateway.myrule;
import com.alibaba.cloud.nacos.NacosDiscoveryProperties;
import com.alibaba.cloud.nacos.ribbon.NacosServer;
import com.alibaba.nacos.api.exception.NacosException;
import com.alibaba.nacos.api.naming.NamingService;
import com.alibaba.nacos.api.naming.pojo.Instance;
import com.netflix.client.config.IClientConfig;
import com.netflix.loadbalancer.AbstractLoadBalancerRule;
import com.netflix.loadbalancer.BaseLoadBalancer;
import com.netflix.loadbalancer.ILoadBalancer;
import com.netflix.loadbalancer.Server;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
/**
* 自定义一个权重负载均衡策略
*/
@Slf4j
public class MyWeightRule extends AbstractLoadBalancerRule {
@Autowired
private NacosDiscoveryProperties discoveryProperties;
@Override
public void initWithNiwsConfig(IClientConfig iClientConfig) {
// 读取配置文件, 并且初始化, ribbon内部基本上用不上
}
/**
* 这个方法是实现负载均衡策略的方法
*
* @param
* @return
*/
@Override
public Server choose(Object key) {
try {
log.info("key:{}", key);
// 调用父类方法, 获取当前使用的负载均衡器
BaseLoadBalancer baseLoadBalancer = (BaseLoadBalancer) this.getLoadBalancer();
// 获取当前服务的名称
String serviceName = baseLoadBalancer.getName();
/**
* namingService: 获取nacos的服务发现API
*/
NamingService namingService = discoveryProperties.namingServiceInstance();
/**
* 根据名称获取服务发现实例
* 在selectOneHealthyInstance中, nacos实现了权重的负载均衡算法
*/
Instance instance = namingService.selectOneHealthyInstance(serviceName);
return new NacosServer(instance);
} catch (NacosException e) {
e.printStackTrace();
}
return null;
}
}第二步: 启用自定义的负载均衡器应用
修改自定义的ribbon config.
package com.personal.www.gateway.config;
import com.lxl.www.ribbonconfig.GlobalRibbonConfig;
import org.springframework.cloud.netflix.ribbon.RibbonClients;
import org.springframework.context.annotation.Configuration;
@Configuration
/*@RibbonClients(value = {
@RibbonClient(name="product", configuration = ProductConfiguration.class),
@RibbonClient(name = "customer", configuration = CustomerConfiguration.class)
})*/
// 使用全局的配置
@RibbonClients(defaultConfiguration = GlobalRibbonConfig.class)
public class CustomeRibbonConfig {
}设置为全局配置GlobalRibbonConfig.class
然后在全局配置中,我们执行当前使用的负载均衡策略是自定义的权重负载均衡策略
package com.personal.www.ribbonconfig;
import com.personal.www.gateway.myrule.MyWeightRule;
import com.netflix.loadbalancer.IRule;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class GlobalRibbonConfig {
@Bean
public IRule getRule() {
// 实现带有权重的负载均衡策略
return new MyWeightRule();
}
}第三步:启动服务,并设置nacos权重

我们看到启动了两台product,一台order. 接下来设置product两台实例的权重
我们看到一个设置为0.1,另一个是0.9, 也就是说如果有10次请求, 基本上都是会打到8083端口上的.
第四步: 浏览器访问连接,测试结果
http://localhost:8080/get/product触发了10次请求,基本上都打到了8083服务器上.
四、实现同集群优先调用原则的负载均衡器
尽量避免跨集群调用
比如,南京集群的product优先调用南京集群的order.北京集群的product优先调用北京集群的order.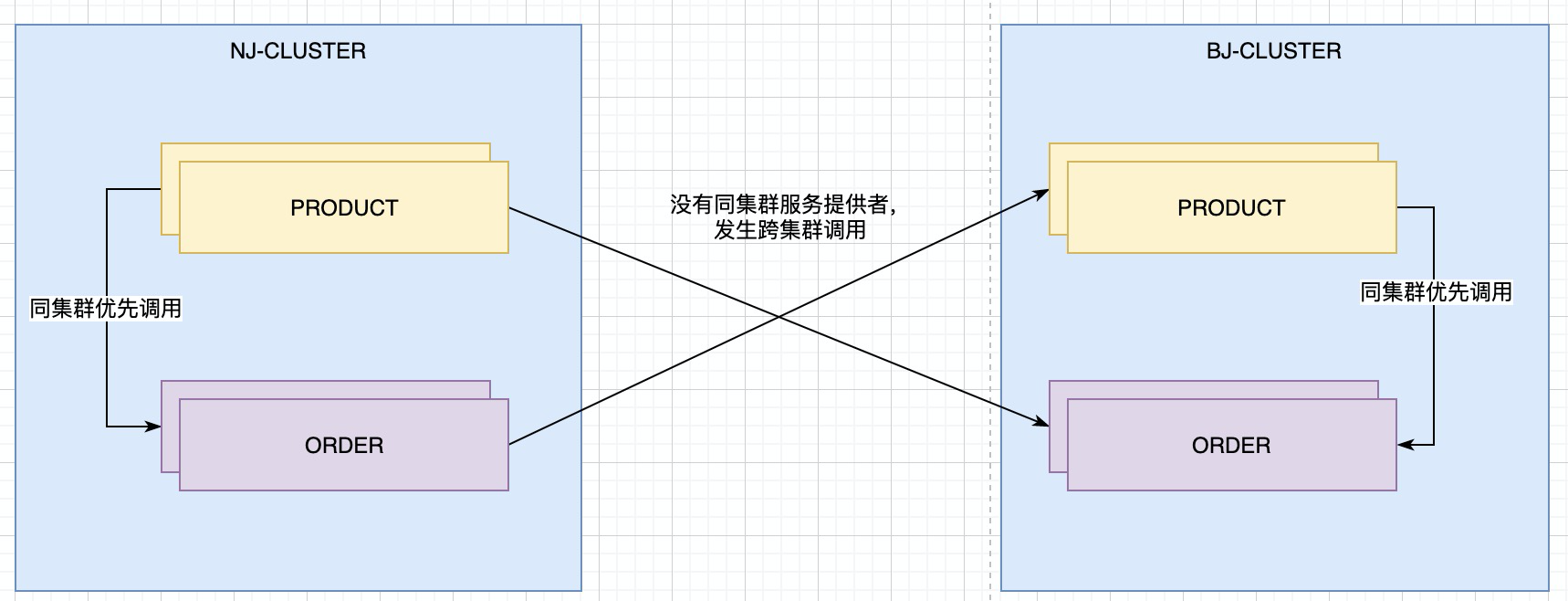
实现如上图所示的功能
我们有product服务和order服务, 假设各有10台. product和order有5台部署在北京集群上, 另外5台部署在南京集群上.
那么当有请求打到南京的product的时候, 那么他调用order要优先调用南京集群的,南京集群没有了,在调用北京集群的.
当有请求打到北京的product的是偶,优先调用北京集群的order,北京没有找到,再去调用南京的order.
第一步: 自定义一个同集群优先策略的负载均衡器
package com.personal.www.gateway.myrule;
import com.alibaba.cloud.nacos.NacosDiscoveryProperties;
import com.alibaba.cloud.nacos.ribbon.NacosServer;
import com.alibaba.nacos.api.exception.NacosException;
import com.alibaba.nacos.api.naming.NamingService;
import com.alibaba.nacos.api.naming.pojo.Instance;
import com.netflix.client.config.IClientConfig;
import com.netflix.loadbalancer.AbstractLoadBalancerRule;
import com.netflix.loadbalancer.BaseLoadBalancer;
import com.netflix.loadbalancer.Server;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.lang.StringUtils;
import org.omg.PortableInterceptor.INACTIVE;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import java.util.ArrayList;
import java.util.List;
/**
* 同集群优先调用--负载均衡策略
*/
@Slf4j
public class TheSameClusterPriorityRule extends AbstractLoadBalancerRule {
@Autowired
private NacosDiscoveryProperties discoveryProperties;
@Override
public void initWithNiwsConfig(IClientConfig iClientConfig) {
}
/**
* 主要实现choose方法
*
* @param o
* @return
*/
@Override
public Server choose(Object o) {
try {
// 第一步: 获取服务所在的集群名称
String clusterName = discoveryProperties.getClusterName();
// 第二步: 获取当前负载均衡器
BaseLoadBalancer loadBalancer = (BaseLoadBalancer) this.getLoadBalancer();
// 第三步: 获取当前服务的实例名称
String serviceName = loadBalancer.getName();
// 第四步: 获取nacos client服务注册发现api
NamingService namingService = discoveryProperties.namingServiceInstance();
// 第五步: 通过namingService获取当前注册的所有服务实例
List<Instance> allInstances = namingService.getAllInstances(serviceName);
List<Instance> instanceList = new ArrayList<>();
// 第六步: 过滤筛选同集群下的服务实例
for (Instance instance: allInstances) {
if (StringUtils.endsWithIgnoreCase(instance.getClusterName(), clusterName)) {
instanceList.add(instance);
}
}
Instance toBeChooseInstance;
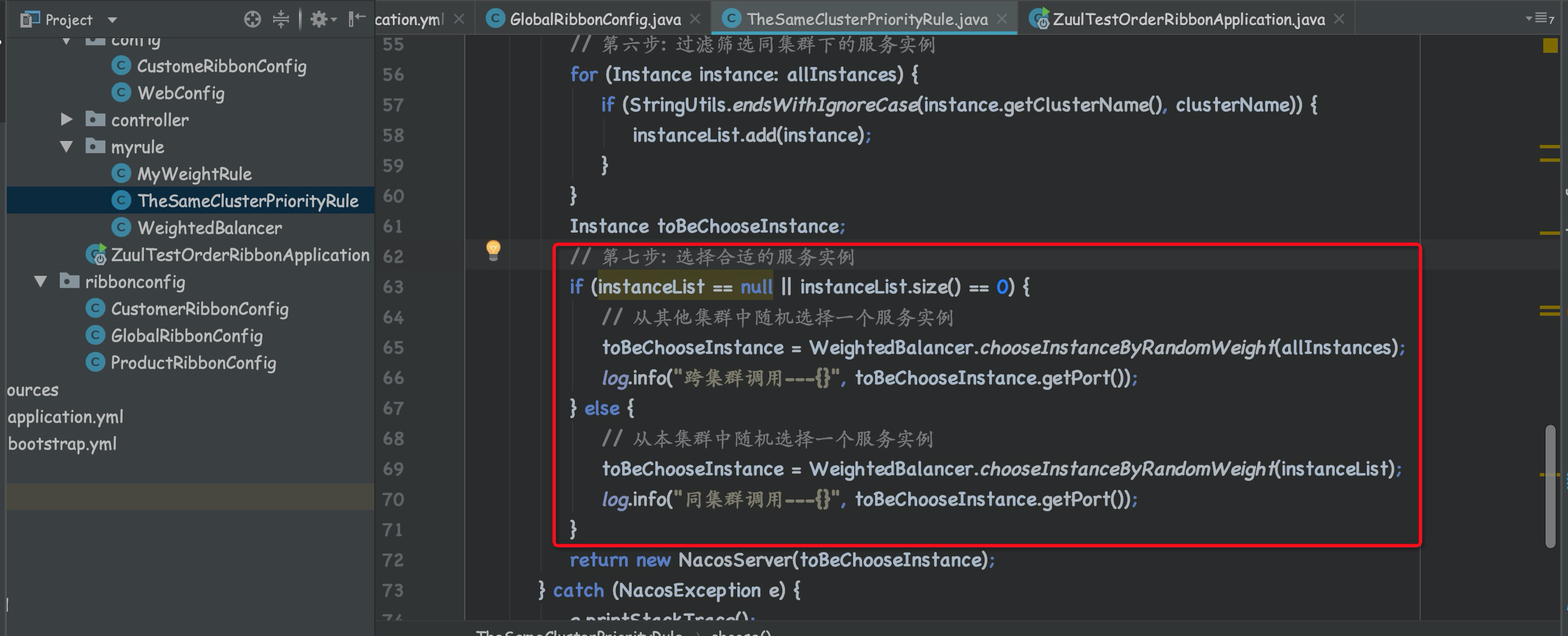
// 第七步: 选择合适的服务实例
if (instanceList == null || instanceList.size() == 0) {
// 从其他集群中随机选择一个服务实例
toBeChooseInstance = WeightedBalancer.chooseInstanceByRandomWeight(allInstances);
log.info("跨集群调用---{}", toBeChooseInstance.getPort());
} else {
// 从本集群中随机选择一个服务实例
toBeChooseInstance = WeightedBalancer.chooseInstanceByRandomWeight(instanceList);
log.info("同集群调用---{}", toBeChooseInstance.getPort());
}
return new NacosServer(toBeChooseInstance);
} catch (NacosException e) {
e.printStackTrace();
}
return null;
}
}
package com.lxl.www.ribbon.myrule;
import com.alibaba.nacos.api.naming.pojo.Instance;
import com.alibaba.nacos.client.naming.core.Balancer;
import java.util.List;
/**
* 根据权重随机选择一个实例
*/
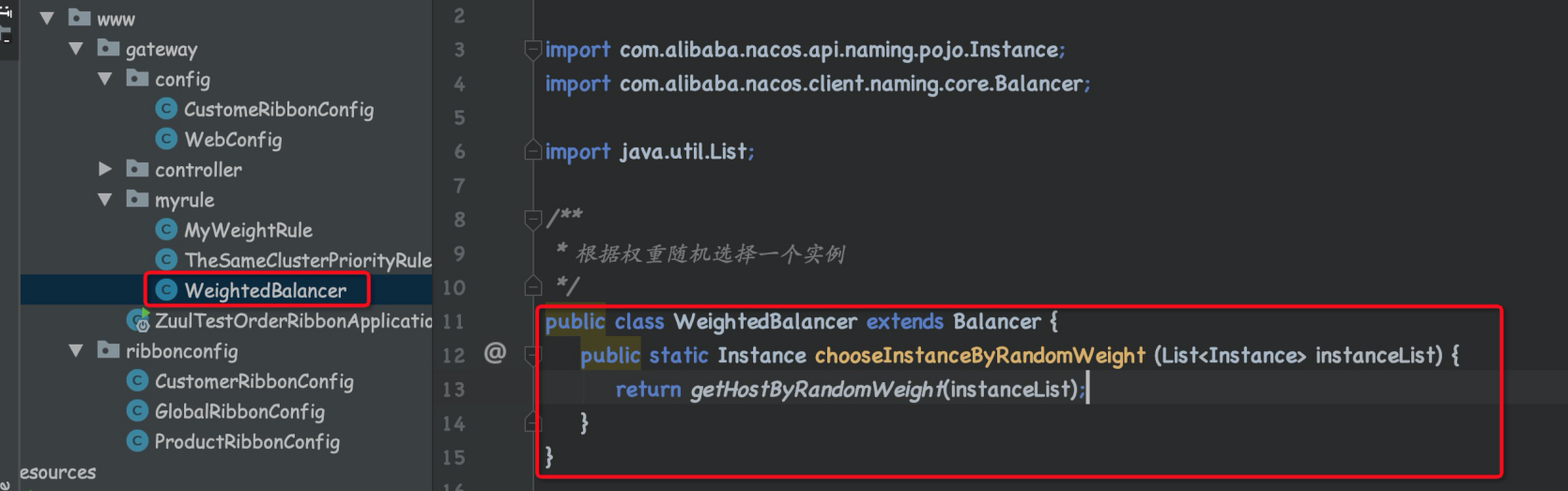
public class WeightedBalancer extends Balancer {
/**
* 根据随机权重策略, 从一群服务器中选择一个
* @return
*/
public static Instance chooseInstanceByRandomWeight (List<Instance> instanceList) {
// 这是父类Balancer自带的根据随机权重获取服务的方法.
return getHostByRandomWeight(instanceList);
}
}第二步: 设置当前的负载均衡策略为同集群优先策略
@Configuration
/*@RibbonClients(value = {
@RibbonClient(name="product", configuration = ProductConfiguration.class),
@RibbonClient(name = "customer", configuration = CustomerConfiguration.class)
})*/
// 使用全局的配置
@RibbonClients(defaultConfiguration = GlobalRibbonConfig.class)
public class CustomeRibbonConfig {
}@Configuration
public class GlobalRibbonConfig {
@Bean
public IRule getRule() {
// 实现带有权重的负载均衡策略
//return new MyWeightRule();
// 实现同集群优先的服务实例
return new TheSameClusterPriorityRule();
}
}第三步: 启动服务

可以看到order服务实例有1台, 所属集群是BJ-CLUSTER, product服务有4台. BJ-CLUSTER和NJ-CLUSTER各两台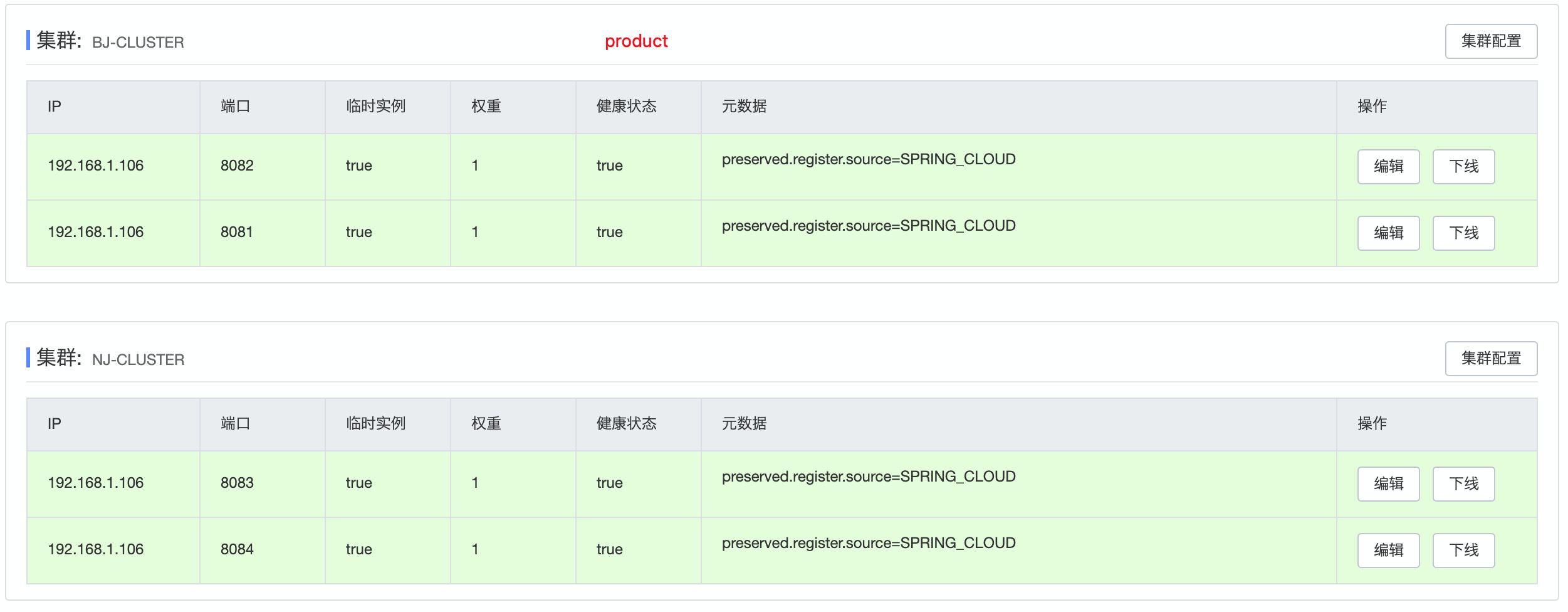
第四步: 访问请求
http://localhost:8080/get/product由于order服务是BJ-CLUSTER,所以,我们看到流量是随机打到了ORDER的BJ-CLUSTER集群上.
停止BJ-CLUSTER集群的两台实例, 现在BJ-CLUSTER集群上没有product的服务实例了,这时在请求,流量就会达到NJ-CLUSTER上.
五、金丝雀发布–实现同版本同集群优先负载均衡策略
金丝雀发布一般先发1台,或者一个小比例,例如 2% 的服务器,主要做流量验证用,也称为金丝雀 (Canary) 测试(国内常称灰度测试)。以前旷工开矿下矿洞前,先会放一只金丝雀进去探是否有有毒气体,看金丝雀能否活下来,
金丝雀发布由此得名。简单的金丝雀测试一般通过手工测试验证,复杂的金丝雀测试需要比较完善的监控基础设施配合,通过监控指标反馈,观察金丝雀的健康状况,作为后续发布或回退的依据。如果金丝测试通过,
则把剩余的 V1 版本全部升级为 V2 版本。如果金丝雀测试失败,则直接回退金丝雀,发布失败。优势和适用场合
优势:
用户体验影响小,金丝雀发布过程出现问题只影响少量用户
适用场合:
- 对新版本功能或性能缺乏足够信心
- 用户体验要求较高的网站业务场景
- 缺乏足够的自动化发布工具研发能力
金丝雀发布, 也称为灰度发布, 是什么意思呢?
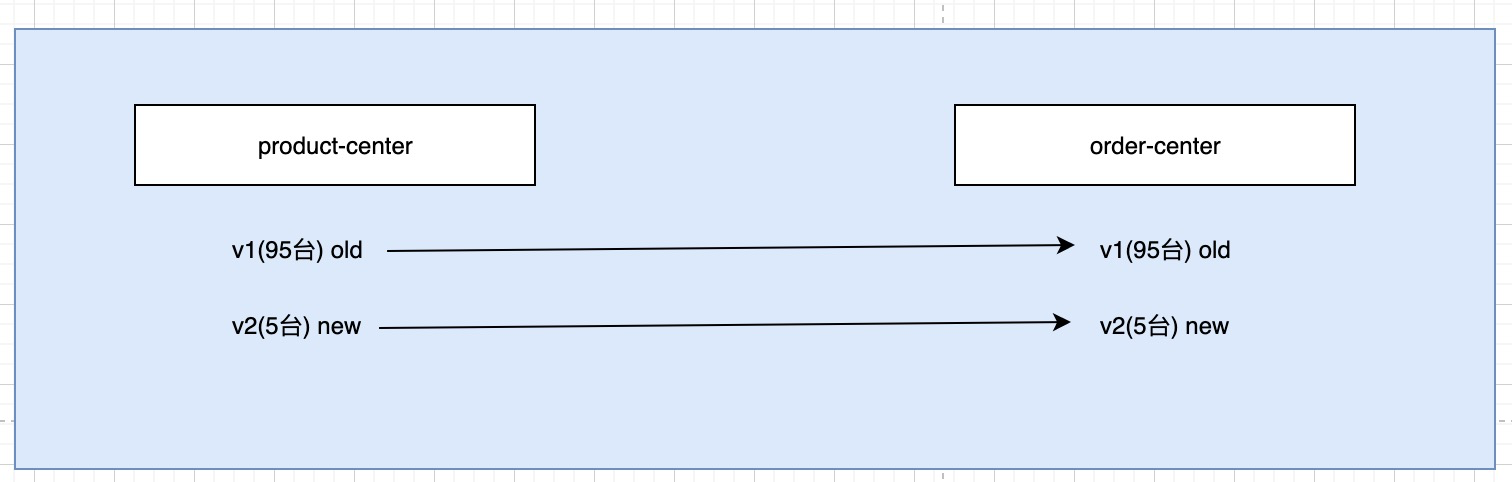
首先, 我们的product服务实例有100台, order服务实例有100台. 现在都是在v1 版本上
然后新开发了一个变化很大的功能, 为了保证效果, 要进行灰度测试
在product-center上发布了5台, 在order-center上发布了5台
那么现在用户的流量过来了, 我们要设定一部分用户, 请求的是v1版本的流量, 而且全部都走v1版本, product-center, order-center都是v1版本
如果过来的用户, 请求的v2版本的流量, 那么product和order都走v2版本.
下面我们要实现的功能描述如下: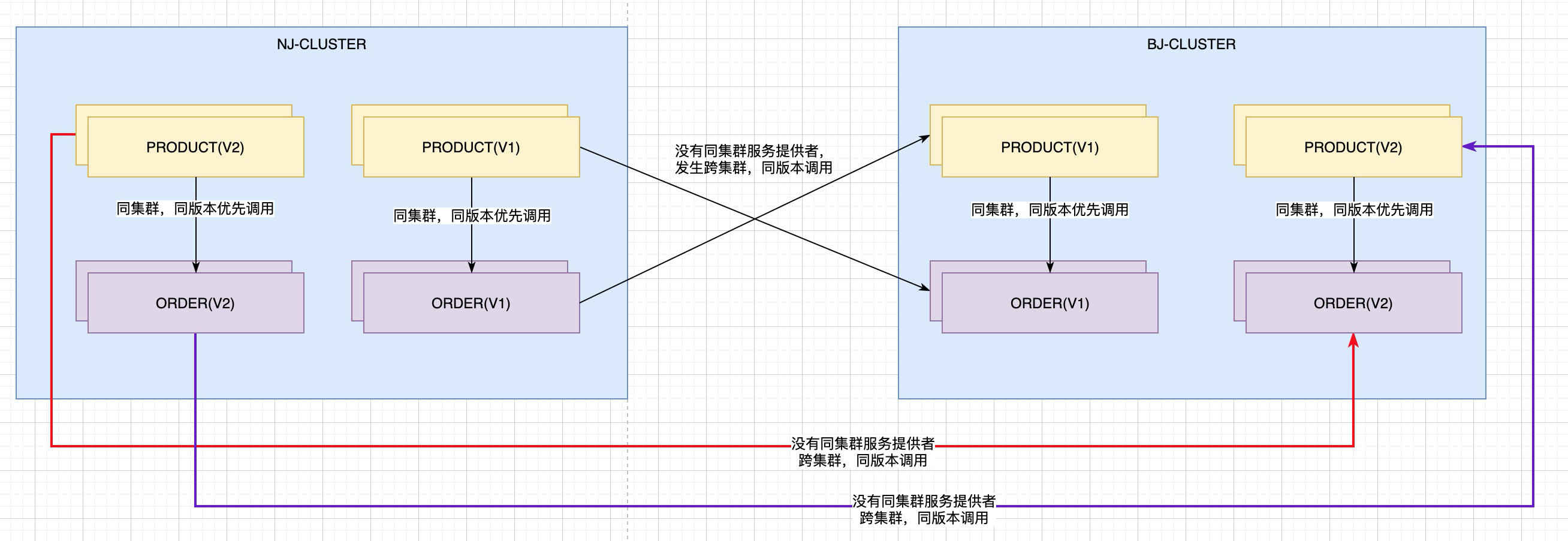
- 同集群,同版本优先调用,
- 没有同集群的服务提供者, 进行跨集群,同版本调用
- 不可以进行不同版本间的调用
也就是说: 南京集群V1版本的product优先调用南京集群V1版本的order, 如果没有南京集群V1版本的order, 那么就调用北京集群V1版本的order, 那么能调用v2版本的么?当然不行.
下面来具体实现一下
第一步: 实现带有版本的集群优先策略的负载均衡算法
package com.personal.www.gateway.myrule;
import com.alibaba.cloud.nacos.NacosDiscoveryProperties;
import com.alibaba.cloud.nacos.ribbon.NacosServer;
import com.alibaba.nacos.api.exception.NacosException;
import com.alibaba.nacos.api.naming.NamingService;
import com.alibaba.nacos.api.naming.pojo.Instance;
import com.netflix.client.config.IClientConfig;
import com.netflix.loadbalancer.AbstractLoadBalancerRule;
import com.netflix.loadbalancer.BaseLoadBalancer;
import com.netflix.loadbalancer.Server;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import java.util.ArrayList;
import java.util.List;
/**
* 同集群优先带版本的负载均衡策略
*/
@Slf4j
public class TheSameClusterPriorityWithVersionRule extends AbstractLoadBalancerRule {
@Autowired
private NacosDiscoveryProperties discoveryProperties;
@Override
public void initWithNiwsConfig(IClientConfig iClientConfig) {
}
@Override
public Server choose(Object o) {
try {
// 第一步: 获取当前服务的集群名称 和 服务的版本号
String clusterName = discoveryProperties.getClusterName();
String version = discoveryProperties.getMetadata().get("version");
// 第二步: 获取当前服务的负载均衡器
BaseLoadBalancer loadBalancer = (BaseLoadBalancer) this.getLoadBalancer();
// 第三步: 获取目标服务的服务名
String serviceName = loadBalancer.getName();
// 第四步: 获取nacos提供的服务注册api
NamingService namingService = discoveryProperties.namingServiceInstance();
// 第五步: 获取所有服务名为serviceName的服务实例
List<Instance> allInstances = namingService.getAllInstances(serviceName);
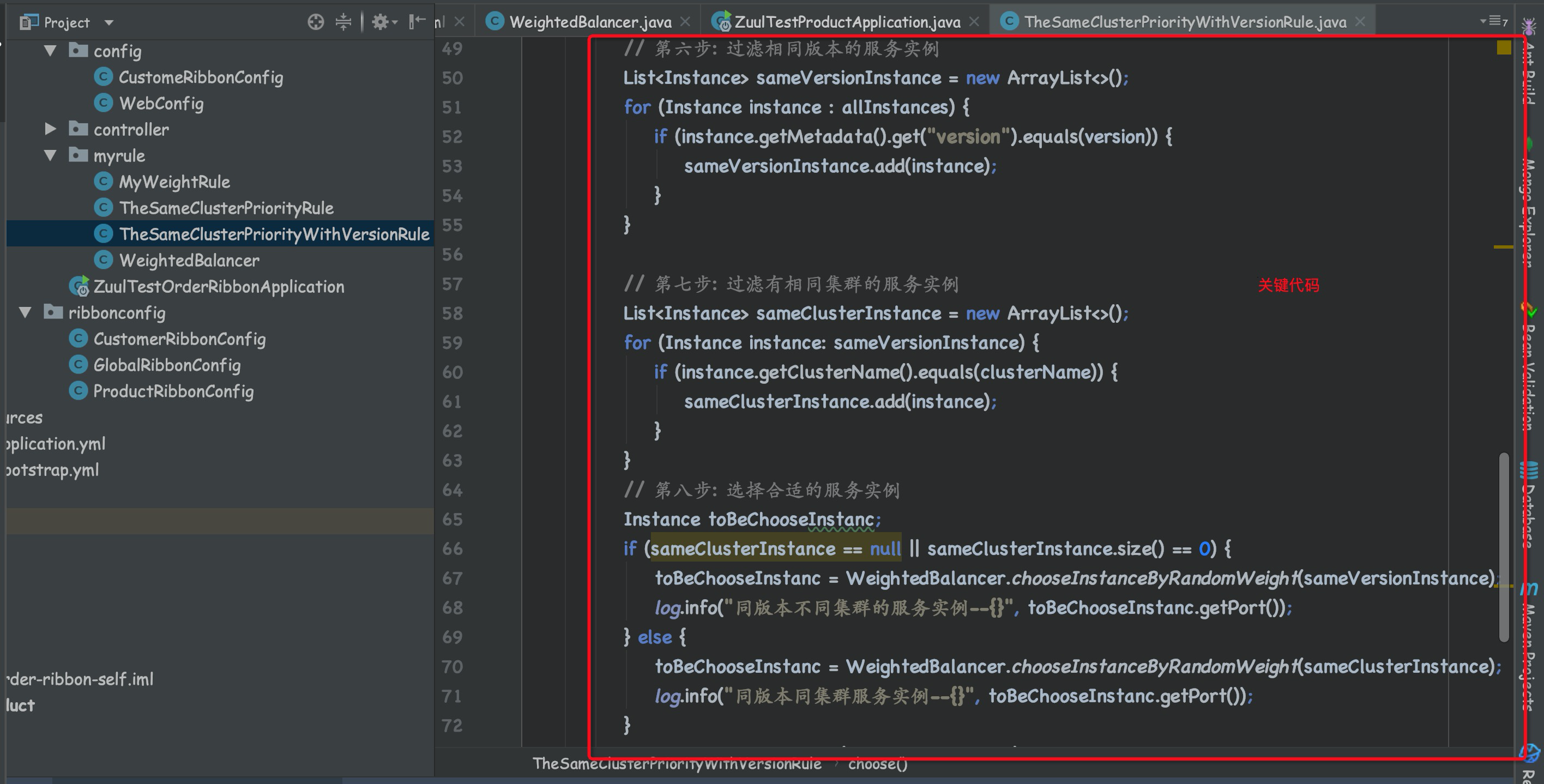
// 第六步: 过滤相同版本的服务实例
List<Instance> sameVersionInstance = new ArrayList<>();
for (Instance instance : allInstances) {
if (instance.getMetadata().get("version").equals(version)) {
sameVersionInstance.add(instance);
}
}
// 第七步: 过滤有相同集群的服务实例
List<Instance> sameClusterInstance = new ArrayList<>();
for (Instance instance: sameVersionInstance) {
if (instance.getClusterName().equals(clusterName)) {
sameClusterInstance.add(instance);
}
}
// 第八步: 选择合适的服务实例
Instance toBeChooseInstanc;
if (sameClusterInstance == null || sameClusterInstance.size() == 0) {
toBeChooseInstanc = WeightedBalancer.chooseInstanceByRandomWeight(sameVersionInstance);
log.info("同版本不同集群的服务实例--{}", toBeChooseInstanc.getPort());
} else {
toBeChooseInstanc = WeightedBalancer.chooseInstanceByRandomWeight(sameClusterInstance);
log.info("同版本同集群服务实例--{}", toBeChooseInstanc.getPort());
}
return new NacosServer(toBeChooseInstanc);
} catch (NacosException e) {
e.printStackTrace();
}
return null;
}
}第二步: 启用自定义负载均衡策略
@Configuration
/*@RibbonClients(value = {
@RibbonClient(name="product", configuration = ProductConfiguration.class),
@RibbonClient(name = "customer", configuration = CustomerConfiguration.class)
})*/
// 使用全局的配置
@RibbonClients(defaultConfiguration = GlobalRibbonConfig.class)
public class CustomeRibbonConfig {
}@Configuration
public class GlobalRibbonConfig {
@Bean
public IRule getRule() {
// 实现带有权重的负载均衡策略
//return new MyWeightRule();
// 实现同集群优先的负载均衡策略
// return new TheSameClusterPriorityRule();
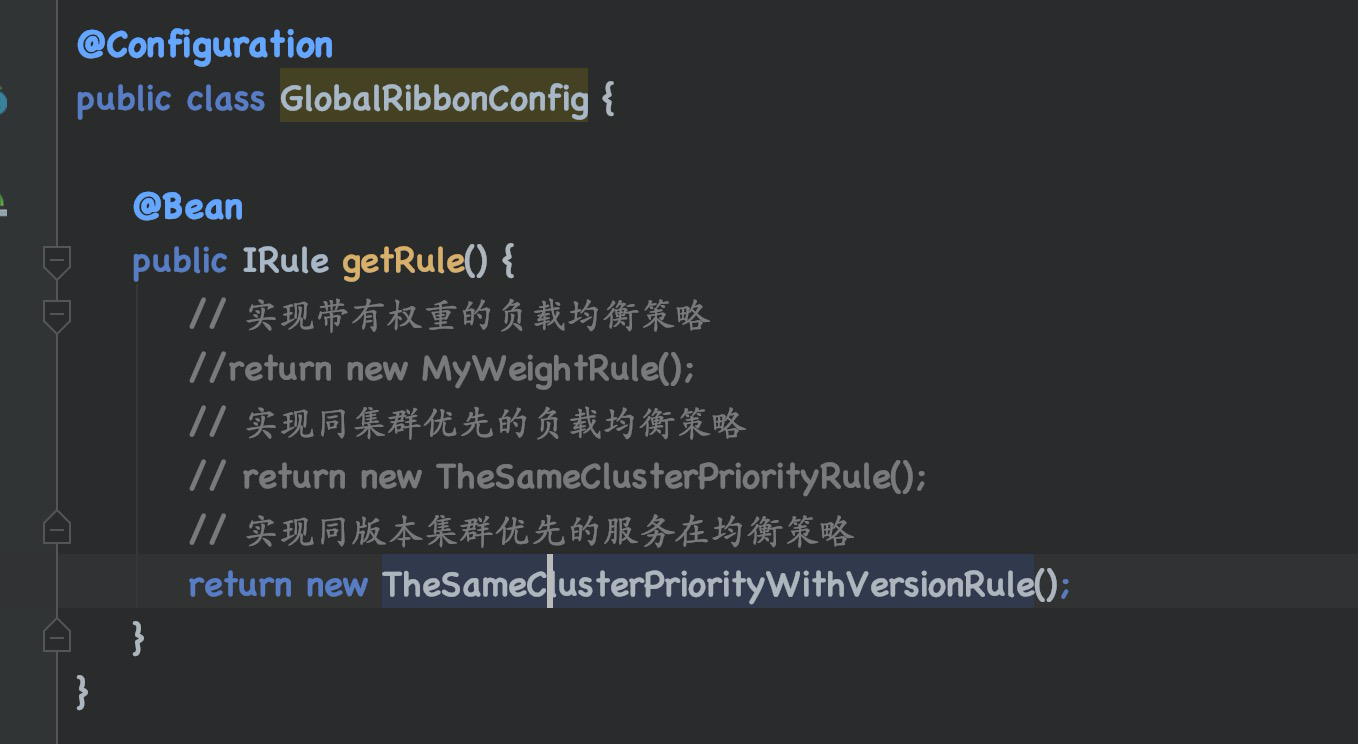
// 实现同版本集群优先的服务负载均衡策略
return new TheSameClusterPriorityWithVersionRule();
}
}第三步:启动服务
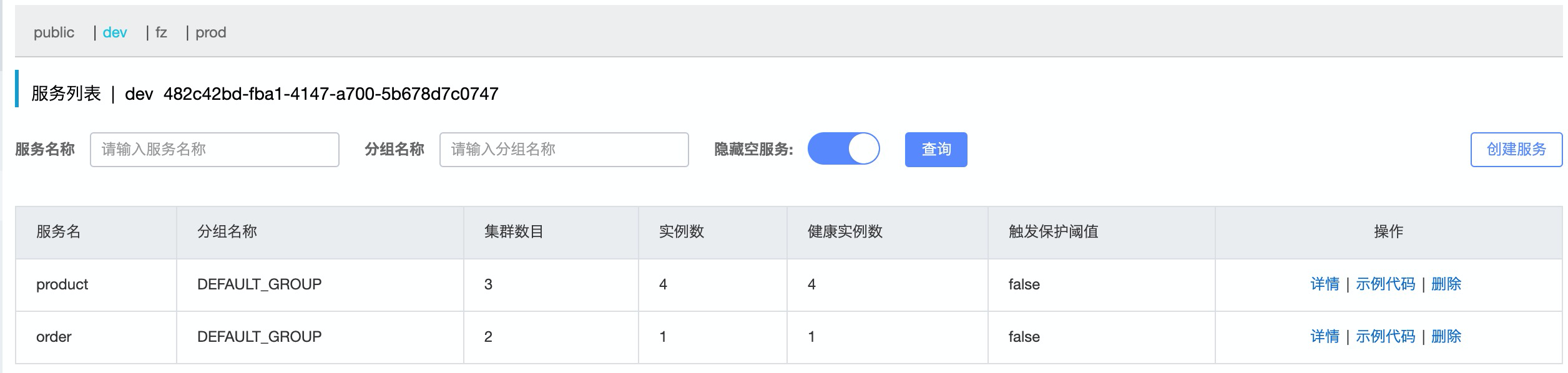
如图,我们启动了两个服务, 一个order, 一个product, 其中order启动了1个实例, product启动了4个实例.
下面来看看order实例的详情
属于北京集群,版本号是v1版本
再来看看product集群的详情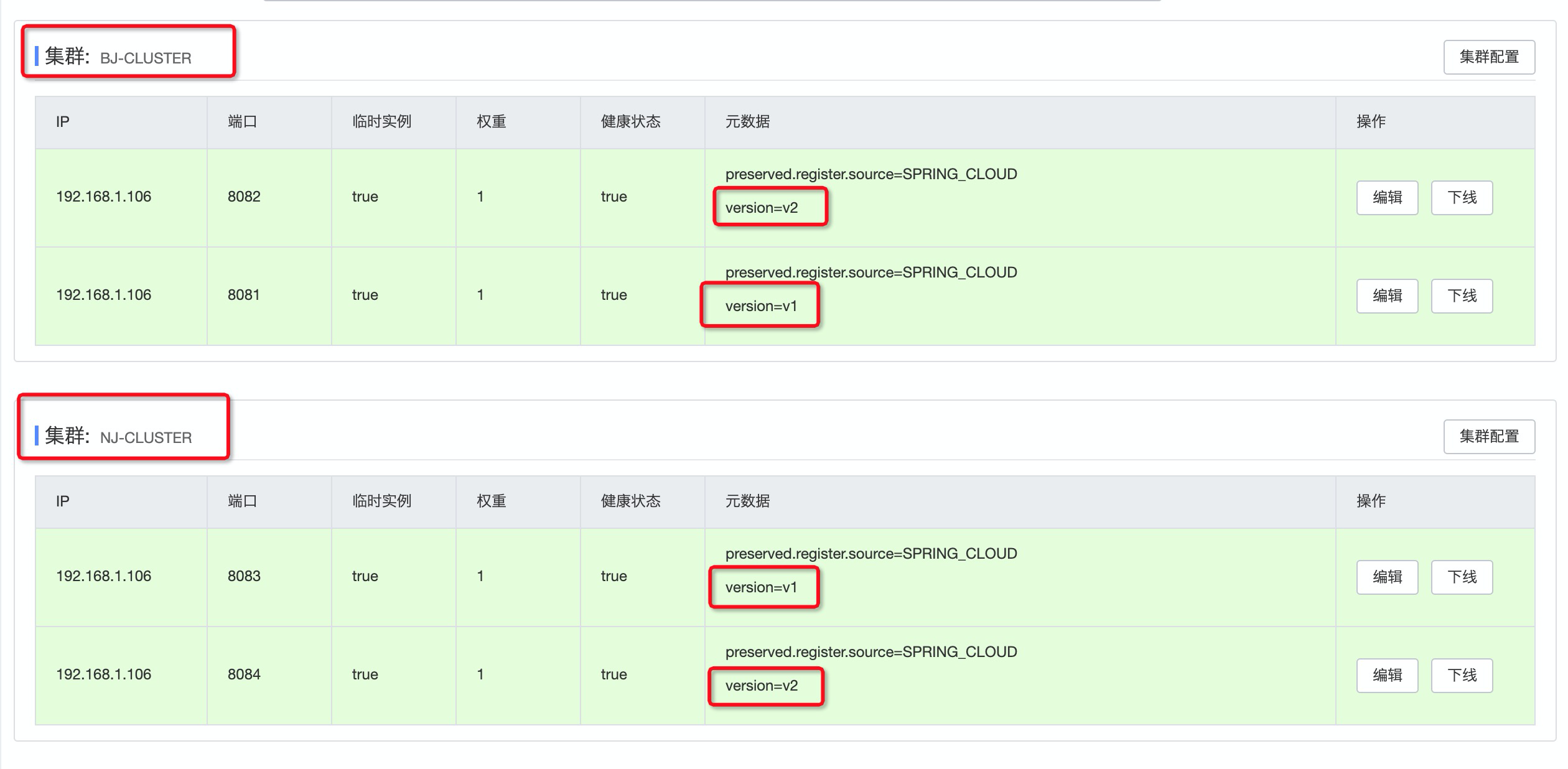
北京集群有两台实例, 一个版本号是v1,另一个是v2
南京集群有两台实例, 一个是v1, 另一个也是v2
第四步: 现在发起请求
http://localhost:8080/get/productorder集群是北京, 版本是version1. 那么服务应该达到哪台服务器呢? 应该打到北京集群的v1版本服务,端口号是8081的服务器.
果然,请求达到了8081服务上, 加入这时候, 北京集群的8081宕机了, 流量应该达到南京集群的v1版本的集群上, 端口号是8083
果然是8083. 那么如果8083也宕机了, 流量会打到v2服务器上么? 没错,不会的, 报错了, 没有服务